

Last Update: February 25, 2025
BY eric
eric
Keywords
Finding the Right Document Processing Tool for Your Workflow
In today's rapidly evolving digital landscape, efficient document processing has become essential for streamlining workflows across various industries. As large language models (LLMs) and AI technologies become more integrated into professional environments, selecting the right document tool can significantly impact productivity, data extraction accuracy, and content management capabilities. Whether you're a researcher analyzing academic papers, a legal professional processing contracts, or a content creator managing diverse document formats, having the appropriate tool for your specific workflow needs is crucial.
Typical Workflow
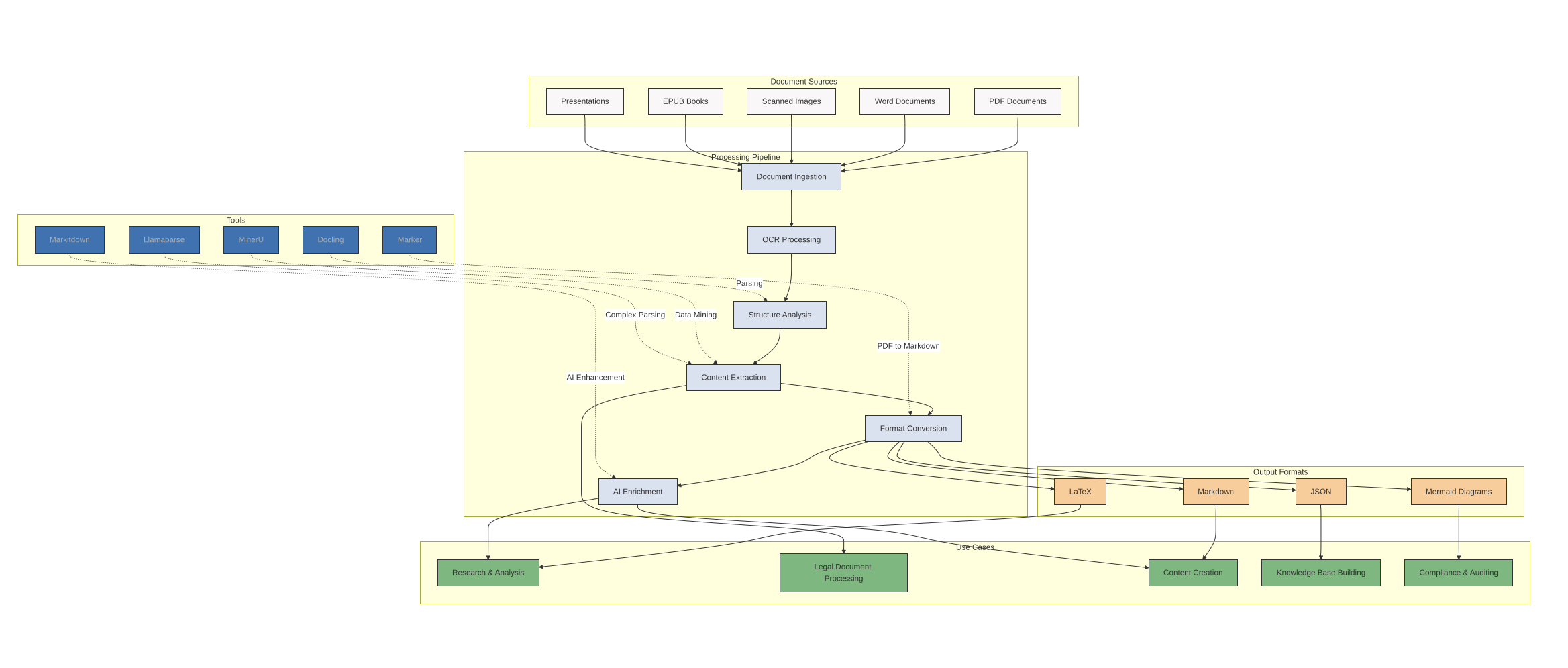
Document Sources
The workflow begins with various document types that organizations typically need to process:
- PDF Documents
- Word Documents (DOCX)
- Scanned Images
- EPUB Books
- Presentations (PPT)
Processing Pipeline
These documents go through several processing stages:
- Document Ingestion - Initial loading and preparation
- OCR Processing - Converting images to machine-readable text
- Structure Analysis - Identifying document layout and components
- Content Extraction - Pulling out relevant information
- Format Conversion - Transforming to target formats
- AI Enrichment - Adding value through AI processing
Tools
Document processing tools range from low-level OCR to complex AI-driven solutions. Some tools are designed for specific workflows, while others offer a range of features:
- Marker: Specializes in PDF to Markdown conversion
- MinerU: Excels at data mining and extraction
- Docling: Focuses on document parsing and structure analysis
- Markitdown: Specializes in AI enhancement and content suggestions
- Llamaparse: Handles complex parsing for various document types
Output Formats
The pipeline produces various output formats:
- Markdown
- JSON
- LaTeX
- Mermaid Diagrams
Use Cases
Finally, the end result can be used in different ways:
- Research & Analysis: Leveraging structured data for insights
- Legal Document Processing: Extracting key information from contracts and legal documents
- Content Creation: Using processed documents for new content development
- Knowledge Base Building: Creating searchable repositories of information
- Compliance & Auditing: Generating structured documentation for regulatory purposes
Overall Flowchart
Document Processing Tools
This article compares five notable document tools—Marker, MinerU, Docling, Markitdown, and Llamaparse—each designed to address different document processing challenges. By examining their technical architectures, key features, and practical advantages and limitations, we aim to help you identify the most suitable solution to enhance your specific workflow requirements.
Marker
Best for: Open-source PDF-to-Markdown conversion with OCR support.
Marker is an open-source tool designed for professionals who need to extract and convert PDF documents into structured Markdown format. Developed by Vik Paruchuri, it provides a lightweight and efficient solution for handling scanned PDFs and formula extraction.
Technical Architecture
Marker leverages a powerful combination of PyMuPDF and Tesseract OCR for document processing, with optional GPU acceleration through the Surya OCR toolkit. The architecture prioritizes efficiency and minimal resource utilization, making it accessible to users with varying computational capabilities. Its open-source foundation encourages community contributions and customizations, allowing for continuous improvements and adaptations to specific use cases.
Key Features
- Focused on PDF-to-Markdown conversion with support for formula-to-LaTeX conversion.
- Embedded image storage and OCR support for scanned PDFs.
- Supports multilingual document processing, though table conversion may misalign and complex formulas have limited accuracy.
Pros & Cons
Pros:
- Open-source and free
- Processing speed is considerably faster than similar tools
Cons:
- Lacks advanced complex layout parsing
- Depends on local GPU resources
MinerU
Best for: AI-powered document mining and knowledge extraction.
MinerU uses AI to extract relevant information from large datasets, making it ideal for researchers and analysts. The tool precisely extracts PDF content by automatically filtering headers and footers, providing comprehensive document processing capabilities.
Technical Architecture
MinerU's sophisticated architecture integrates multiple advanced AI models, including LayoutLMv3 for document understanding and YOLOv8 for object detection, creating a comprehensive multimodal parsing system. This robust framework enables precise handling of complex document elements such as tables, mathematical formulas, and embedded images. The system requires Docker containerization and CUDA-compatible hardware for optimal performance, reflecting its enterprise-grade design intended for organizations with significant computational resources.
Key Features
- Precise extraction of PDF content, automatically filtering headers/footers.
- Supports conversion from EPUB, MOBI, and DOCX to Markdown and JSON.
- Multilingual OCR (84 languages) with UniMERNet optimization for formula recognition.
Pros & Cons
Pros:
- Supports CPU and GPU
- Supports both API and GUI interfaces
Cons:
- Table processing is slow
- Setup requires a GPU-dependent complex configuration
Docling
Best for: Lightweight document parsing and quick text manipulation.
Docling is a modular tool designed for parsing documents and transforming them into structured formats. It extracts text and metadata from PDFs, converting them into structured formats like JSON and CSV. The tool also supports scanned PDFs but may require OCR integration for optimal results.
Technical Architecture
Docling's architecture is built upon the Unstructured framework and LayoutParser library, creating a flexible system that prioritizes local processing capabilities. This design choice enhances data privacy and reduces dependency on external services, making it particularly suitable for organizations with sensitive information. The modular construction allows developers to integrate only the components they need, streamlining resource usage while maintaining compatibility with the broader IBM ecosystem.
Key Features
- Parses PDF, DOCX, PPTX, preserving reading order and table structures.
- Supports OCR and LangChain integration.
- Outputs Markdown or JSON, making it ideal for RAG knowledge bases.
Pros & Cons
Pros:
- IBM ecosystem-compatible
- Supports mixed document formats
Cons:
- Requires CUDA
- Some features depend on commercial models
Markitdown
Best for: Markdown-based documentation with AI-enhanced suggestions.
Markitdown is geared towards content creators and developers who prefer working in Markdown while leveraging AI-powered writing assistance. The tool can convert various document formats to Markdown and provides AI-powered enhancements for content creation.
Technical Architecture
Markitdown represents Microsoft's approach to document processing, featuring an architecture that seamlessly integrates GPT-4 capabilities for enhanced content analysis and generation. This integration enables intelligent processing beyond mere format conversion, offering context-aware suggestions and automated content improvements. The system's design reflects Microsoft's commitment to developer-friendly tools, with an architecture that balances cloud-based AI processing with local execution options, making it adaptable to various deployment scenarios while maintaining consistent performance.
Key Features
- Supports conversion from Word, Excel, PPT, images (OCR), and audio (speech-to-text) to Markdown.
- Can batch process ZIP files.
- Generates image descriptions (requires OpenAI API), though PDF structure may be lost in conversion.
Pros & Cons
Pros:
- Best format support
- Developer-friendly with Python API/CLI
Cons:
- Relies on external APIs
- Some features require paid models
Llamaparse
Best for: Advanced document parsing with deep AI processing.
Llamaparse is an AI-powered parsing tool that excels in document understanding and automated content structuring. It uses AI to parse both structured and unstructured PDFs, extracting tables, images, and text with high accuracy. The tool can handle multi-column layouts and scanned images, making it versatile for complex document processing.
Technical Architecture
Llamaparse's architecture is specifically optimized for Retrieval-Augmented Generation (RAG) workflows, implementing a sophisticated system that leverages Azure OpenAI services and KDB AI vector databases. This architectural choice enables highly efficient semantic search capabilities and context-aware document understanding. The system employs a multi-stage processing pipeline that first analyzes document structure, then extracts semantic meaning, and finally generates structured outputs in various formats. This approach allows for handling documents with complex layouts and mixed content types while maintaining semantic relationships between elements.
Key Features
- Parses complex PDFs with tables, charts, and figures, outputting Markdown, LaTeX, and Mermaid diagrams.
- Supports knowledge graph generation for enterprise-level compliance and security.
Pros & Cons
Pros:
- High accuracy
- Supports semi-structured data optimization
Cons:
- Processing speed is slow
- Limited free-tier usage
- Requires API key
Conclusion
Choosing the right document tool depends on your specific workflow needs:
- For open-source PDF-to-Markdown conversion: Marker
- For AI-powered data mining: MinerU
- For lightweight parsing: Docling
- For Markdown-based documentation: Markitdown
- For advanced AI-powered document structuring: Llamaparse
Each tool has its strengths and weaknesses, so selecting the right one will depend on your specific use case and workflow requirements. By integrating the appropriate document processing tool, you can significantly enhance your productivity, improve data extraction accuracy, and streamline your content management processes. Whether you need simple parsing, AI-driven insights, or enhanced document structuring, there's a tool available to optimize your specific workflow needs.
Latest Articles





Previous Article

Feb 26, 2025
Empowering Your Ideas with AI: Exploring New LLM Chat Tools
In this post, we explore two new open-source LLM chat tools: Cherry Studio and ChatBox, highlighting their unique features and LLM integrations.
Next Article

Feb 24, 2025
Handy Linux (Ubuntu) Commands for Video Processing
In this post, I will show you a list of handy Linux (Ubuntu) commands for video processing.